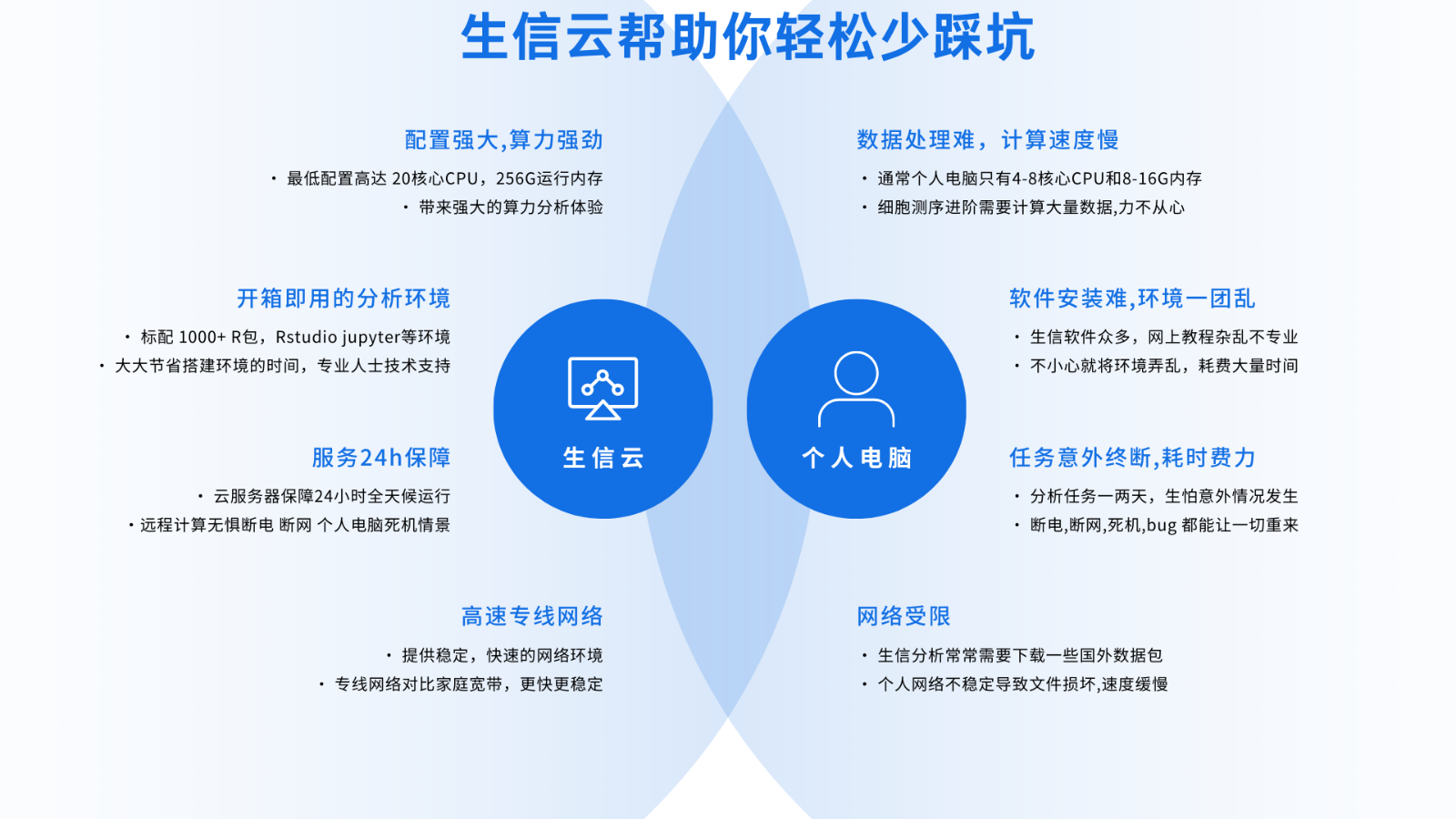
integrative omics processing platform enables next-generation personalized treatment development. These powerful systems are designed to analyze massive datasets and reveal clinically relevant patterns. Leveraging high-performance algorithms and standardized workflows, they enhance discovery throughput and rigor.
Scalable Compute for Large-Scale Genomic Analysis
Sequencing and high-throughput assays create huge datasets requiring specialized computing capacity. Highly scalable servers provide the processing power needed for genome-scale analyses.
- Elastic provisioning allows infrastructures to absorb spikes in processing demand.
- Many solutions leverage distributed computing, container orchestration, and parallelism for throughput.
- Scalable bioinformatics servers are instrumental for a wide range of applications, including genome sequencing, variant calling, and phenotype prediction.
The cloud era delivers shared infrastructure that researchers worldwide can provision for intensive analyses.
On-Demand Bioinformatics Clouds for High-Throughput Genomics
Sequencing innovation has created massive data growth, necessitating cloud-grade compute and storage. Such clouds deliver instant access to compute clusters, object storage, and curated bioinformatics toolchains.

Scalable, Distributed Computing for Thorough Bioinformatics Workflows
Research pipelines for genomics and proteomics need extensive processing capacity and optimized tooling. On-premises systems are effective but may require heavy investment to meet intermittent high workloads.
Using cloud compute, teams can process large cohorts and run computationally intensive models effectively.
Moreover, cloud-based elasticity reduces capital expenditure and simplifies multi-site collaboration on shared datasets.
The Future of Bioinformatics: Specialized Cloud Solutions
As genomics and multi-omics expand, bespoke cloud infrastructures are being built to support domain workflows. They offer end-to-end toolchains for sequence analysis, annotation, and ML-driven discovery in regulated contexts.
This flexibility helps democratize bioinformatics capabilities, enabling broader participation from varied institutions.
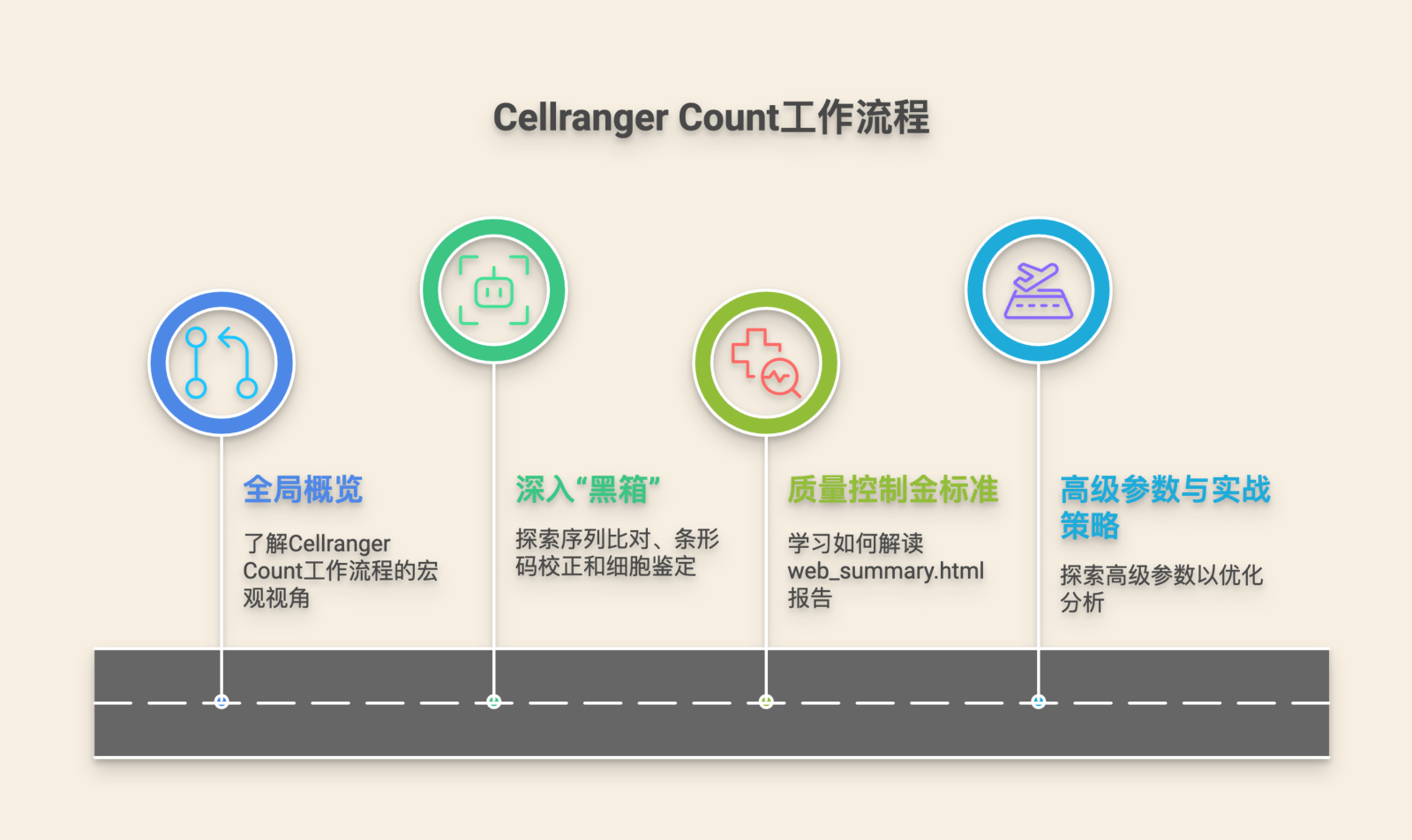
On-Demand Compute to Streamline Genomic Workflows
On-demand servers allow projects to scale resources temporarily without long-term hardware investments. Temporarily scaled servers remove resource bottlenecks and accelerate completion of complex workflows.
Many providers offer ready-to-run images with alignment, variant-calling, and annotation tools installed. With infrastructure prepped, researchers redirect effort to experimental questions and downstream validation.
Cloud-Based Bioinformatics Services That Empower Discovery
Cloud-delivered bioinformatics services are revolutionizing research by packaging compute, software, and data into accessible offerings. Such platforms provide the compute and tooling necessary to turn data into biological and clinical insight.
- Managed bioinformatics services scale with project needs to facilitate high-throughput analysis.
- Cloud platforms make it easier to collaborate on code, workflows, and annotated datasets across labs.
- Advanced computational methods and AI help identify biomarkers and prioritize variants for study.
On-Demand Bioinformatics for Personalized Treatment Strategies
Increased genomic and phenotypic data yields more precise stratification for personalized treatments. These platforms apply advanced analytics to stratify patients, prioritize therapeutics, and evaluate treatment efficacy. Actionable outputs help clinicians select targeted therapies, enroll patients in trials, and track treatment efficacy.
Computational Discovery: The Power of Bioinformatics Analysis
Bioinformatics computing reveals complexities of biological systems by applying powerful algorithms and domain tools to large datasets. Deep data analyses detect low-frequency events, structural variants, and pathway perturbations.

To decode complex biology, researchers depend on algorithmic, reproducible, and scalable computational frameworks.
Scalable, Dedicated Bioinformatics Systems for Next-Gen Research
The data-intensive nature of bioinformatics calls for infrastructures that scale while maintaining reproducibility. Leveraging distributed compute and cloud-native patterns, they enable rapid iteration of complex bioinformatics tasks.
- On-demand cloud resources give teams the agility to right-size environments per project phase.
- Continual refinement of analytics and libraries helps address novel biological questions efficiently.
cloud-based bioinformatics analysis service
Next-gen systems underpin innovation in therapeutics, diagnostics, and bio-based industries through scalable compute.
A Robust Bioinformatics Toolset for Scientific Exploration
Comprehensive platforms provide the instruments researchers need to convert data into biological knowledge. Included modules span read alignment, variant calling, genome annotation, phylogenetic pipelines, and structure prediction tools. The platform’s web interface, tutorials, and workflow templates enable users of varying skill to run complex analyses reproducibly.